在 Java 中如何编解码
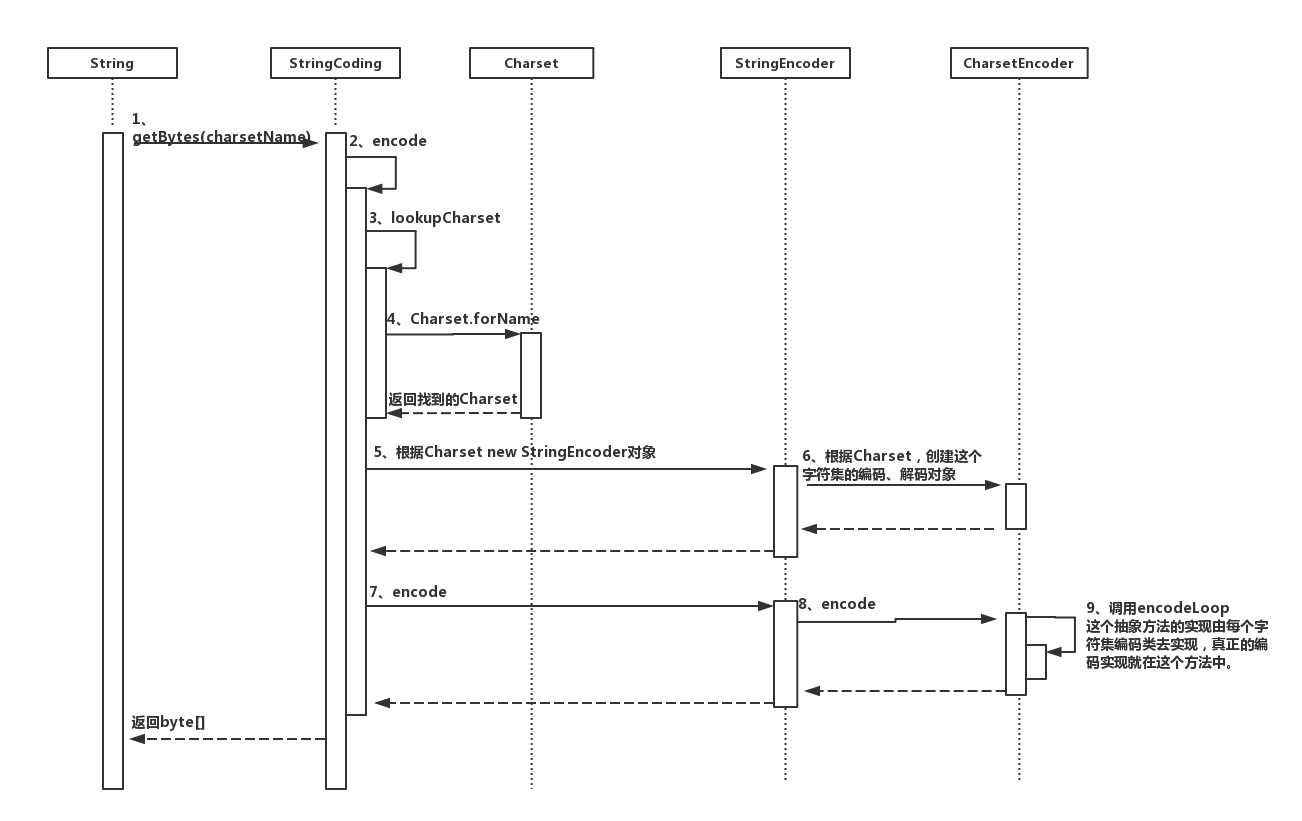
String.getBytes(charsetName) 编码过程时序图:
几种编码格式的比较
对于中文字符,GB2312、GBK、UTF-8、UTF-16 都能处理,GB2312 与 GBK 编码规则类似,GBK 范围更大,所以将 GB2312 与 GBK 进行比较,应该选择 GBK。UTF-16、UTF-8 都是处理 Unicode 编码,UTF-16 的编码效率更高,从字符到字节之间的转换更简单,进行字符串操作也更好,适合在本地磁盘和内存之间使用,可以进行字符到字节之间的快速切换,但不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,UTF-8 更适合网络传输。UTF-8 对 ASCII 字符采用单字节存储,单个字符损坏不影响后面的其它字符,在编码效率上介于 GBK 和 UTF-16 之间,UTF-8 在编码效率和编码安全性上做了平衡,是理想的中文编码方式。
在 Java web 中汲及的编解码
I/O 操作会引起编码,而大部份 I/O 引起的乱码都是网络 I/O,数据经过网络传输时都是以字节为单位,所以所有数据都必须能够被序列化为字节,在 Java 中数据要被序列化,必须继承 Serializable 接口。
如果把整型数字 1234567 当作字符来存储,采用 UTF-8 编码将会占用 7 个字节,采用 UTF-16 占用 14 个字节,但是把它当成 int 类型的数字来存储时则只需 4 个字节。所以看一段文本的大小,只看字符本身的长度是没有意义的,即使是一样的字符,采用不同的编码最终存储的大小也会不同,所以从字符到字节一定要看编码类型。
用户从浏览器端发起一个 HTTP 请求,需要存在编码的地方是 URL、Cookie、Parameter。服务器端接收到 HTTP 请求后要解析 HTTP ,其中 URI、Cookie、和 POST 表单参数需要解码,服务器端可能还需要读取数据库中的数据,本地或网络中其它地方的文本文件,这些数据都存在编码问题。当 Servlet 处理完所有请求的数据后,需要将这些数据再编码,通过 Socket 发送到用户请求的浏览器,再经过浏览器解码。
参考
- 《深入分析Java Web技术内幕》(修订版) 许令波 著